
特征选择打开ator: final feature set problem

Hi,
I have 2 questions about FEATURE SELECTION operator.
1. After running the algorithm it generates a few feature sets but selects a certain feature set according to 'balance to accuracy' parameter. For example, this is the Pareto front from which a feature set is chosen for balance = 0.8:
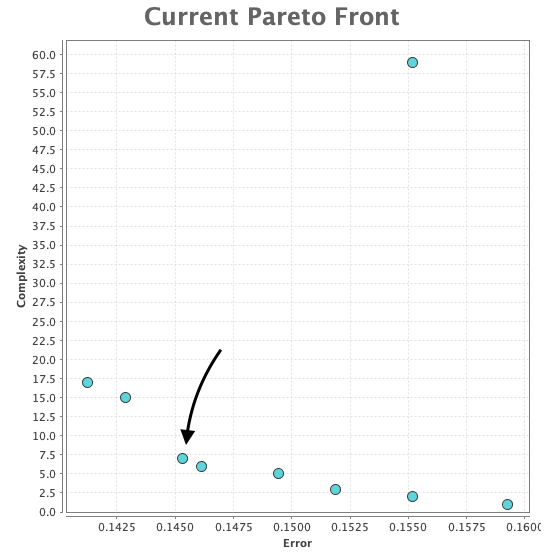
This certain set has 7 features and I may want to also check the bigger (15) or the smaller (5) sets to compare. Is there an easy way to access other feature sets here? Otherwise to obtain another set I have to change the balance parameter and run the process over again, which takes time.
2. This is part of my process which uses feature selection:

So, what am I doing here:
Why this happens? Can it happen that these 2 features relevant to training set only, but not relevant to test set (remember I use not random but consecutive split of data)?
More generally, is it the correct approach I am using here, or should I always run feature selection algorithm on the full data?
Thanks.
I have 2 questions about FEATURE SELECTION operator.
1. After running the algorithm it generates a few feature sets but selects a certain feature set according to 'balance to accuracy' parameter. For example, this is the Pareto front from which a feature set is chosen for balance = 0.8:
This certain set has 7 features and I may want to also check the bigger (15) or the smaller (5) sets to compare. Is there an easy way to access other feature sets here? Otherwise to obtain another set I have to change the balance parameter and run the process over again, which takes time.
2. This is part of my process which uses feature selection:
So, what am I doing here:
- divide the whole data into training and testing sets using time series variable ( on a time axis : ==== train ==== | == test ==> )
- perform feature selection on training set
- apply selected features to both subsets
- train GLM model on train set
- apply GLM model on test set
Why this happens? Can it happen that these 2 features relevant to training set only, but not relevant to test set (remember I use not random but consecutive split of data)?
More generally, is it the correct approach I am using here, or should I always run feature selection algorithm on the full data?
Thanks.

1
Best Answer
-
 IngoRM
Administrator, Moderator, Employee, RapidMiner Certified Analyst, RapidMiner Certified Expert, Community Manager, RMResearcher, Member, University ProfessorPosts:1,751
IngoRM
Administrator, Moderator, Employee, RapidMiner Certified Analyst, RapidMiner Certified Expert, Community Manager, RMResearcher, Member, University ProfessorPosts:1,751 RM Founder
Hi,On the first question: the second port ("population") delivers a collection of all Feature Sets, you can select feature sets out of this collection with the operator Select.On the second question: the general setup looks good. And yes, it can still happen that selected feature are selected out by the learner again. It is likely that they would have been deselected by the AFE eventually to reduce complexity further, it just did not happen (yet). This is more likely if the selected feature set is on or close to a vertical in the Pareto front BTW.Cheers,Ingo
RM Founder
Hi,On the first question: the second port ("population") delivers a collection of all Feature Sets, you can select feature sets out of this collection with the operator Select.On the second question: the general setup looks good. And yes, it can still happen that selected feature are selected out by the learner again. It is likely that they would have been deselected by the AFE eventually to reduce complexity further, it just did not happen (yet). This is more likely if the selected feature set is on or close to a vertical in the Pareto front BTW.Cheers,Ingo
 7
7
Answers
Vladimir
http://whatthefraud.wtf